感谢本站网友 华南吴彦祖、软媒用户1392612 的线索投递!
刚刚,OpenAI 深夜直播,GPT-4o 的原生图像生成大升级!奥尔特曼亲自上阵组队,演示了自拍变梗图、相对论漫画等功能,不过相对隔壁谷歌发布的新模型,OpenAI 的这波动作着实有点不够看。
就在谷歌刚刚扔出地表最强模型 Gemini 2.5 Pro 不久,OpenAI 也有动作了。
奥尔特曼亲自带队,展示了 GPT-4o 图像生成技术的各种大升级,比如制作梗图、文本渲染、多轮交互生成和指令遵循等。

整个直播中最亮的演示,莫过于这张官方玩梗的表情包了。

目前,这项功能已经在 ChatGPT 和 Sora 中,向所有 Plus、Pro、Team 和免费用户推出。

当然,新版 Sora 生图的时间,也比以往更长了。但 OpenAI 看来,生图的质量和其具备的世界知识,让用户值得等待那多出的几秒。
GPT-4o 原生图像生成来了!
在直播中,奥尔特曼介绍道,从今天起,ChatGPT 中的原生图像生成功能正式推出!
GPT-4o 的全模态能力,从此也融合进了 Sora 中。
OpenAI 多模态研究的负责人 Gabe 介绍说,两年前刚开始这个项目时,他对于 GPT-4 这个强大的模型会怎样原生支持图像模型非常好奇。
一年后,当模型完成训练时,他看到了令人兴奋的迹象。从 GPT-2 以来,他已经很久没有这种感觉 —— 这是一个疯狂时刻。
给出以下 prompt,GPT-4o 就生成了符合要求的图像,完全还原了要求。


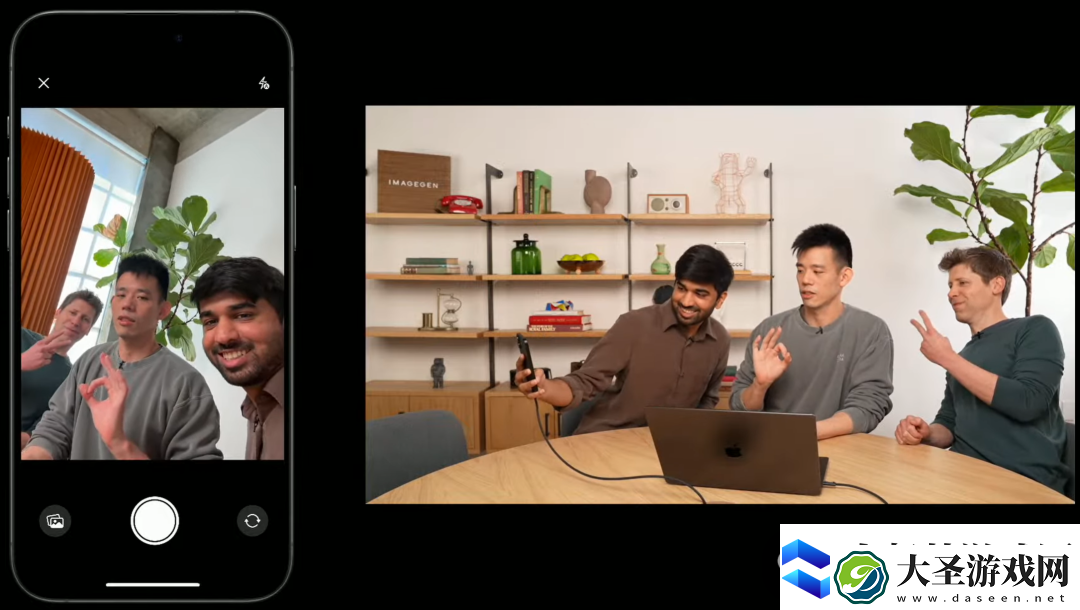
接下来,三个人用手机来了张自拍,GPT-4o 立刻把三人自拍转换成了动漫风格的版本。
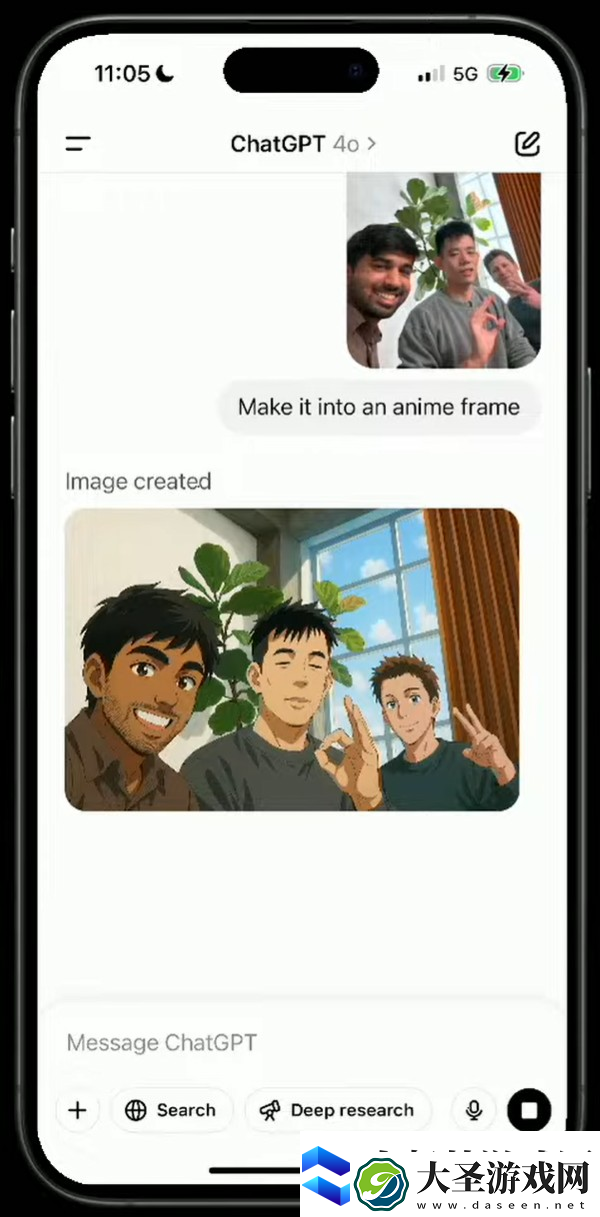
甚至他们开始官方玩梗,让模型添加一段「Feel The AGI」在图片上,一张表情包就此诞生。
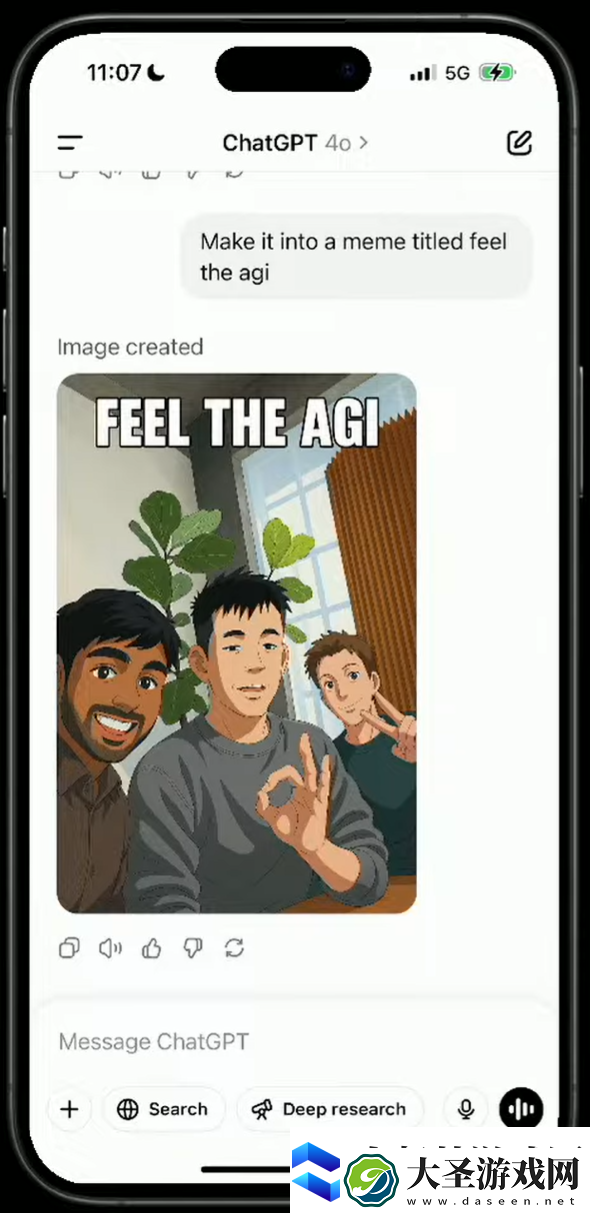
这个过程,就体现了 4o 作为全能模型的强大能力。
因为它不仅仅是一个语言模型,还包括图像、音频,所有输入和输出的模态。它可以理解、生成这些模态,并且无缝地在它们之间工作。
用 OpenAI 的话说,「我们终于迈向了这种真正集成的多模态模型」。
接下来,他们让模型画出一幅描述相对论的漫画,要求通俗易懂,还要加入一些幽默元素。
这个提示词非常模糊,因此看看模型会生成什么样的图,就格外令人期待了。果然,生成效果令人惊喜。
注意,这个过程中,模型很可能利用了自己的世界知识,对提示词进行了扩展。

然后,他们给了模型一张卡片,希望生成同样风格的图像,但要求主角不再是卡片中的巨猫国王,而是某位研究者的狗狗。


另外,卡片上还需要出现一些细节,比如模型的名字和年份,以及狗狗的体重和身高。
可以看到,生成图像在文本渲染方面非常惊艳,所有数据都准确无误。

最后一个演示,是基于此前几人生成的内容,制作一个纪念币。
而且,还要求图使用了一个特殊的十六进制代码,且加上生成图像的文本和日期。
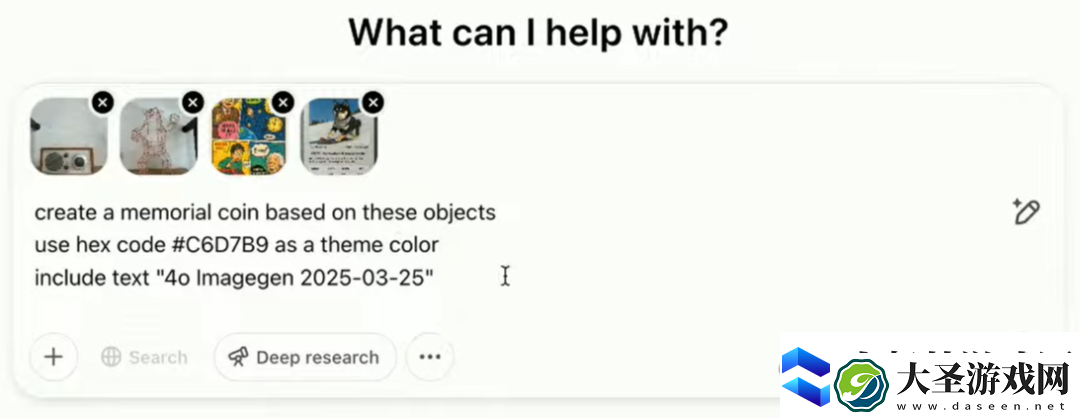
可以看到,生成结果非常惊艳!此前曾出现的艺术熊、收音机、爱因斯坦漫画、研究者的狗狗以及模型名称和日期,全部都出现在了纪念币上。

模型之所以精准完成这样复杂的要求,是因为它是用非自回归的方式训练的,因此它能够理解上下文中的文本和多张图片,以非常和谐的方式在纪念币上呈现出来。
和 GPT-4o 聊天,定制各种图像
